Linux常用命令大全¶
1. 文件与目录操作¶
touch - 创建文件¶
若文件不存在则创建文件,若存在则修改文件的时间(存取时间和更改时间)
mv - 移动/重命名文件和目录¶
mkdir - 创建目录¶
cp - 复制文件和目录¶
cp a.txt b.txt // 复制a.txt到b.txt,如果b.txt不存在,则创建,存在则覆盖
cp -i a.txt b.txt // 如果b.txt存在,覆盖b.txt之前,会询问用户
cp a.txt b.txt dir1/ // 复制a.txt, b.txt 到dir1目录
cp *.txt dir1/ // 复制txt文件到dir1目录
cp -r dir1/*.txt dir2/ // 递归地复制dir1目录下的txt文件到dir2目录下
cp -u a.txt b.txt // 当b.txt不存在,或者a.txt新于b.txt时候才会复制
rm - 删除文件和目录¶
rm file1 // 删除file1
rm -i file1 // 删除文件file1,询问用户确认
rm -r dir1/ // 递归删除dir1以及目录下所有文件
rm -rf dir1/ dir2/ // 递归删除dir1,dir2目录,即使目录dir2不存在也不会终止
ln - 创建链接¶
stat - 显示文件的详细信息¶
stat查看文件时候,会显示三种类型时间:分别是Access time,Modify time,Change time。
- access time:表示我们最后一次访问(仅仅是访问,没有改动)文件的时间。比如more,less,cat,tail等命令都会更改atime
- modify time:表示我们最后一次修改文件的时间。touch会更改这三种类型时间
- change time:表示我们最后一次对文件属性改变的时间,包括权限,大小,属性等等。chmod,chown会更改此时间。
stat a.txt // 显示文件的mtime,atime,ctime
ls -l a.txt // 列出文件的mtime
ls -lc a.txt // 列出文件的ctime
ls -lu a.txt // 列出文件的atime
2. I/O重定向¶
标准输入,输出和错误,在shell内部它们为文件描述符0,1和2
ls -l dir1/ >> ls-output.txt // 重定向ls命令输出的内容到ls-output.txt文件,>等同于1>
ls -l /usr/bintmp 2>ls-error.txt // 重定向标准错误输出到ls-error.txt
ls -l /bin/usr > ls-output.txt 2>&1 // 重定向标准输出和错误到同一个文件
ls -l /usr /usr/bintmp 2>ls-error.txt 1>ls-output.txt // 错误重定向到ls-error.txt 输出重定向到ls-output.txt
ls /usr/bin | tee -a ls.txt | grep zip //tee 从stdin读取数据,并同时输出到stdout和文件。tee命令相当于管道的一个T型接头, -a表示追加
nginx -c nginx.conf > /dev/null 2>&1// 屏蔽标准和错误输出
3. 包管理¶
不同的 Linux 发行版使用不同的打包系统。一般而言,大多数发行版分别属于两大包管理技术阵营: Debian 的”.deb”,和红帽的”.rpm”。也有一些重要的例外,比方说 Gentoo, Slackware,和 Foresight,但大多数会使用这两个基本系统中的一个。
软件包管理系统通常由两种工具类型组成:底层工具用来处理这些任务,比方说安装和删除软件包文件, 和上层工具完成元数据搜索和依赖解析。
表3.1主要的包管理系统家族
| 包管理系统 | 发行版 (部分列表) | 上层工具 | 底层工具 |
|---|---|---|---|
| Debian Style (.deb) | Debian, Ubuntu, Xandros, Linspire | apt-get, aptitude | dpkg |
| Red Hat Style (.rpm) | Fedora, CentOS, Red Hat Enterprise Linux, OpenSUSE, Mandriva, PCLinuxOS | yum | rpm |
一个rpm包的名称分为包全名和包名,包全名如httpd-2.2.15-39.el6.centos.x86_64.rpm,包全名中各部分的意义如下:
| 符号 | 说明 |
|---|---|
| httpd | 包名 |
| 2.2.15 | 版本号,版本号格式[ 主版本号.[ 次版本号.[ 修正号 ] ] ] |
| 39 | 软件发布次数 |
| el6.centos | 适合的操作系统平台以及适合的操作系统版本 |
| x86_64 | 适合的硬件平台,硬件平台根据cpu来决定,有i386、i586、i686、x86_64、noarch或者省略,noarch或省略表示不区分硬件平台 |
| rpm | 软件包后缀扩展名 |
// 检查是否安装过某软件包
rpm -qa | grep "软件或者包的名字"
dpkg -l | grep "软件或者包的名字"
yum list installed | grep "软件名或者包名"
4. 权限与进程¶
id – 显示用户身份号¶
chmod - 改变文件模式¶
表4.1 chmod 命令符号表示法
| 符号 | 说明 |
|---|---|
| u | "user"的简写,意思是文件或目录的所有者 |
| g | 用户组 |
| o | "others"的简写,意思是其他所有的人 |
| a | "all"的简写,是"u", "g"和“o”三者的联合 |
如果没有指定字符,则假定使用”all”。执行的操作可能是一个“+”字符,表示加上一个权限, 一个“-”,表示删掉一个权限,或者是一个“=”,表示只有指定的权限可用,其它所有的权限被删除
chmod 755 a.txt // 将文件权限设置成755
chmod a+x a.txt // 所用组都赋予x权限
chmod u+x,go=rw a.txt //给文件拥有者执行权限并给组和其他人读和执行的权限。多种设定可以用逗号分开
umask - 设置默认权限¶
su - 切换用户¶
sudo - 使用其他身份执行命令¶
sudo su - // 切换到root用户
sudo nginx -s reload // 以root用户身份执行nginx配置重载
sudo -u www-data top // 已指定用户身份(www-data)执行top命令
chown - 更改文件所有者和用户组¶
chown tinker a.txt // 将a.txt文件所有者改为tinker,文件用户组不变
chown tinker:tony a.txt // 将a.txt文件所有者改为tinker,文件用户组改为tony
chown :tony a.txt //将a.txt文件的用户组改为tony,所有者不变
chown tinker: a.txt // 将a.txt文件所有者改成tinker,用户组改为tinker登录系统时候,所属的用户组
chown -aG sudo tinker // 将用户加入sudo用户组
password - 更改用户密码¶
ps - 报告当前进程快照¶
ps aux // 查看当前允许进程
ps -ef | more // 查看当前运行的所有进程(包含进程的父进程信息)
ps -A --sort=-rss -o comm,pmem,pcpu | uniq -c |head -15 // 按进程内存占用大小,从大到小来排序。RSS表示实际分配的内存大小
ps -eo comm,pmem,pcpu --sort=-%cpu | head -10 // 按进程消耗cpu资源大小,从小大到大排序。--sort=-%cpu表示使用从大到小。-e和-A是一样的。
ps -c nginx --no-header | wc -l // 统计nginx进程数量。--no-header表示不答应头部
ps -axjf // 打印进程树
ps -p 1924 -o lstart // 查看进程ID等于1924的进程创建时间
ps -eLf | grep java | wc -l // 查看java线程数
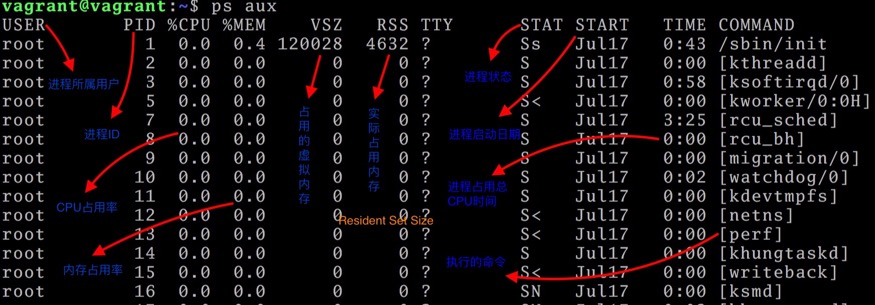
ps内容说明
| 项 | 说明 |
|---|---|
| %CPU | 进程的cpu占用率 |
| %MEM | 进程的内存占用率 |
| VSZ | 进程所使用的虚存的大小 |
| RSS | 进程使用的驻留集大小或者是实际内存的大小 |
| TTY | 与进程关联的终端(tty) |
| STAT | 进程的状态 |
| START | (进程启动时间和日期) |
| TIME | (进程使用的总cpu时间) |
| COMMAND | (正在执行的命令行命令) |
| NI | (nice)优先级 |
| PRI | 进程优先级编号 |
| PPID | 父进程的进程ID(parent process id) |
| SID | 会话ID(session id) |
| WCHAN | 进程正在睡眠的内核函数名称;该函数的名称是从/root/system.map文件中获得的 |
| FLAGS | 与进程相关的数字标识 |
STAT值有:
| 值 | 含义 |
|---|---|
| R | running正在运行或准备运行 |
| S | sleeping休眠 |
| I | idle空闲 |
| Z | 僵死 |
| D | 不可中断的睡眠,通常是I/O |
| P | 等待交换页 |
| W | 换出,表示当前页面不在内存 |
| N | 低优先级任务 |
| T | terminate终止 |
| W | 进入内存交换(从内核2.6开始无效) |
| < | 高优先级 |
| L | 有些页被锁进内存 |
| + | 位于后台的进程组 |
| l | 多线程,克隆线程 |
| s | 包含子进程 |
top - 动态查看进程¶
top命令是常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况
常见选项列表:
| 选项 | 说明 |
|---|---|
| -u user | 查看特定用户user的进程 |
| -c | 显示完整命令 |
| -H | 以线程模式执行 top,等同于交互式命令 H。默认情况下以进程模式执行 top,进程模式下,一个进程下的所有线程归总后显示一行 |
| -i | 不显示任何闲置(idle)或无用(zombie)的进程 |
| -p pid | 只显示指定进程 ID 的进程信息。可以指定多个 PID,最多为 20 个,格式为 -p PID1,PID2,PID3...。特别地,pid 为 0 表示 top 命令本身。如果想显示所有进程信息,无需关闭 top 命令,只需要执行交互式命令 =、u 或 U 即可。 |
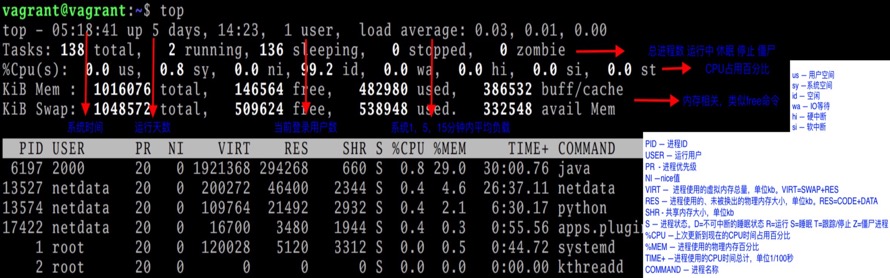
上图说明:
第一行:时间相关和任务队列信息
- 05:18:41 当前时间
- up 5 days, 14:23 运行时间,分钟
- 1 user 当前等于用户数
-
load average: 0.03, 0.01, 0.00 当前系统负载,跟uptime命令一样,说明如下:
三个值是系统在1分钟、5分钟、15分钟内平均负载。系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。
对于系统负载,我们可以类比成高速公路上跑汽车情况。单核CPU服务器,满负载情况,也就是车几乎挨着车,但不堵塞,秩序正常,此时的负载值是1。如果多核CPU情况,满负载值就会是 n * 1,其中n为cpu核数。
第二行:进程信息统计数据
- 138 total 总的进程数
- 2 running 正在运行的进程数
- 136 sleeping 休眠的进程数
- 0 stopped 停止的进程数
- 0 zombie 僵尸进程数
第三行:CPU统计数据
- 0.0 us 用户空间占用CPU百分比
- 0.8 sy 内核空间占用CPU百分比
- 0.0 ni 用户进程空间内改变过优先级的进程占用CPU百分比
- 99.2 id 空闲CPU时间百分比,如果这个值过低,表明系统CPU存在瓶颈
- 0.0 wa 等待I/O的CPU时间百分比,如果这个值过高,表明IO存在瓶颈
- 0.0 hi 硬中断(Hardware IRQ)占用CPU百分比
- 0.0 si 软中断(Software IRQ)占用CPU百分比
- 0.0 st 虚拟机(虚拟化技术)占用百分比
第四行:物理内存的统计数据
- 1016076 total 物理内存总量
- 146564 free 空闲内存总量
- 482980 used 已使用的物理内存总量
-
386532 buff/cache 用作内核缓存的内存量
注意:free 内存表示尚未被内核占用的空闲内存,但是被内核占用用于 buffer 和 cache 的内存,实际上是可以被进程使用的,内核并不把这些可被重新使用的内存算到 free 中,因此在 Linux 上 free 内存会越来越少,但不用为此担心
第五行: 交换分区(即虚拟内存)的统计数据
- 1048572 total 交换区总量
- 509624 free 空闲交换区总量
- 538948 used 已使用的交换区总量
- 332548 avail Mem 实际可用物理内存总量
第六行为空行
前面五行称为汇总区(Summary Area)。从第7行开始,显示各个进程的状态信息,称为任务区(Task Area),各列含义如下:
| 列名 | 说明 |
|---|---|
| PID | 进程id |
| USER | 进程所有者 |
| PR | 进程优先级,范围为0-31,数值越低,优先级越高 |
| NI | nice值。范围-20到+19,用于调整进程优先级,新的进程优先级 PR(new)=PR(old)+nice,所以nice负值表示高优先级,正值表示低优先级 |
| VIRT | 进程使用的虚拟内存总量,单位 KB |
| RES | Resident Memory Size,进程使用的、未被换出的物理内存大小,单位 KB |
| SHR | 共享内存大小,单位 KB |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=停止 t=跟踪 Z=僵尸进程 |
| %CPU | 上次更新到现在的 CPU 时间占用百分比。注意,在多核或多 CPU 环境中,如果进程是多线程的,而 top 不是在线程模式下运行的,该值由多个核的值累加,可能会大于 100% |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的 CPU 时间总计,单位 1/100 秒 |
| COMMAND | 进程名称(命令名/命令行) |
交换模式下命令
| 命令 | 结果 |
|---|---|
| P | 进程列表按CPU使用大小降序排序 |
| M | 进程列表按内存使用大小降序排序 |
| T | 进程列表按照累计时间大小降序排列 |
| N | 进程列表按照PID排序 |
| b | 进入高亮模式,行和列的背景高亮 |
| x | 高亮被选中排序的列,top命名默认使用cpu列表排序的,默认cpu列会高亮 |
| y | 高亮显示正在运行的任务,即某一行进程 |
| > | 右移选择排序列 |
| < | 左移选择排序列 |
| k | 终止一个进程。默认的终止的信号是15 |
| o | 根据列来过滤进程。 按下等号(=)会清除掉过滤条件 |
| E | 扩增(Extend)汇总区内存显示单位,从 KB、MB、GB、TB、PB 到 EB 循环切换 |
| e | 扩增(Extend)任务区内存显示单位,从 KB、MB、GB、TB、PB 到 EB 循环切换 |
| H | 以线程(tHread)模式展示任务区,每个线程单独显示一行。默认是进程模式 |
| u | 显示指定用户的进程 |
| c | 显示命令的绝对路径 |
| q | 退出top交换模式 |
| R | 反转排序 |
| m | 切换显示内存显示方式,以内存条占比形式显示 |
| k | 杀死(Kill)指定进程,默认信号为15(SIGTERM) |
| 1 | 显示或隐藏每个 CPU 核心的使用信息,即影响第三行 CPU 信息显示方式 |
| L | 在进程列表中搜索字符串 |
| = | 显示所有进程信息。可用打破-p选项,交互命令o只显示部分进程,恢复默认进程列表 |
| f | 进入字段管理窗口管理显示的字段,前面带星号的字段是默认显示的 |
交互命令o或O的筛选器格式:
<字段名><运算符><选择值>
运算符可以是=、<、>。具体示例比如COMMAND=nginx,表示筛选COMMAND是nginx的进程。%CPU>3表示cpu负载大于3进程。%CPU>0.0筛选cpu负载大于0的进行,注意是0.0,不能是0
jobs – 列出任务¶
bg – 把任务放到后台执行¶
fg – 把任务放到前台执行¶
kill - 给进程发送信号¶
kill [-signal] PID...
如果在命令行中没有指定信号,那么默认情况下,发送 TERM(终止)信号。
表4.2 常用信号
| 编号 | 名字 | 含义 |
|---|---|---|
| 1 | HUP | 挂起。许多守护进程也使用这个信号,来重新初始化。这意味着,当发送这个信号到一个守护进程后, 这个进程会重新启动,并且重新读取它的配置文件 |
| 2 | INT | 中断。实现和 Ctrl-c 一样的功能,由终端发送。通常,它会终止一个程序 |
| 3 | QUIT | 退出 |
| 9 | KILL | 杀死。这个信号很特别。鉴于进程可能会选择不同的方式,来处理发送给它的信号,其中也包含忽略信号,这样呢,从不发送Kill信号到目标进程。而是内核立即终止 这个进程。当一个进程以这种方式终止的时候,它没有机会去做些“清理”工作,或者是保存劳动成果。 因为这个原因,把 KILL 信号看作杀手锏,当其它终止信号失败后,再使用它 |
| 11 | SEGV | 段错误。如果一个程序非法使用内存,就会发送这个信号。也就是说, 程序试图写入内存,而这个内存空间是不允许此程序写入的 |
| 15 | TERM | 终止。这是 kill 命令发送的默认信号。如果程序仍然“活着”,可以接受信号,那么这个信号终止 |
| 18 | CONT | 继续。在停止一段时间后,进程恢复运行 |
| 19 | STOP | 停止。这个信号导致进程停止运行,而没有终止。像 KILL 信号,它不被 发送到目标进程,因此它不能被忽略 |
| 20 | TSTP | 终端停止。当按下 Ctrl-z 组合键后,终端发送这个信号。不像 STOP 信号, TSTP 信号由目标进程接收,且可能被忽略 |
| 28 | WINCH | 改变窗口大小。当改变窗口大小时,系统会发送这个信号。 一些程序,像 top 和 less 程序会响应这个信号,按照新窗口的尺寸,刷新显示的内容 |
按下ctrl+c组合键时产生SIGINT信号(中断信号), ctrl+\产生SIGQUIT信号(退出信号),ctrl+d是默认的文件结束符
killall - 给多个进程发送信号¶
killall [-u user] [-signal] name...
给匹配特定程序或用户名的多个进程发送信号
pstree - 显示树形结构进程列表¶
pgrep - 查看进程id¶
pmap¶
5. 文件查找¶
locate - 通过名字来查找文件¶
locate命令其实是“find -name”的另一种写法,但是要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库(/var/lib/locatedb),这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,所以使用locate命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。
whereis - 搜索程序名¶
whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。
which - 查命令¶
which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
find – 强大的查找命令¶
find ~ | wc -l // 统计家目录文件数
find ~ -type d | wc -l // 统计家目录下目录数量
find ~ -type f | wc -l // 统计家目录下文件数量
find ~ -type f -name "\*.JPG" -size +1M | wc -l // 查找所有文件名匹配 通配符模式“*.JPG”和文件大小大于1M 的文件
find ~ -type f -name '*.BAK' -delete // 删除扩展名为“.BAK”(这通常用来指定备份文件) 的文件
find ~ -type f -name '*.BAK' -print // 查看找到的文件,find默认是-print,即找到的每一行一换行符结束,-print0找到的每一行以null字符('\0')结束
find . -name 'index.php' -print0 | hd
find . -name 'index.php' -print | hd // 比较print和print0区别
find ~ -type f -name 'foo*' -exec ls -l '{}' ';' // {}是当前路径名的符号表示,分号是要求的界定符 表明命令结束。
find ~ -type f -name 'foo*' -ok ls -l '{}' ';' // 使用 -ok 行为来代替 -exec,在执行每个指定的命令之前,会提示用户
find ~ -type f -name 'foo*' -exec ls -l '{}' + // 把末尾的分号改为加号,就激活了find命令的一个功能,
// 把搜索结果结合为一个参数列表, 然后执行一次所期望的命令
find playground -type f -name 'file-A' | wc -l // 查找名字为file-A的文件
find playground \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
find playground \( -type f -not -perm 0600 -exec chmod 0600 '{}' ';' \)
-or \( -type d -not -perm 0711 -exec chmod 0700 '{}' ';' \)
find ~ -empty // 查找home目录下的所有空文件
find ~ -type f -size 0 // 跟上面一条命令功能一样
find ~ -type d -empty // 查找所有空目录
find ~ -iname "hello.php" // 查找hello.php文件
find . -not -name ".sh" -maxdepth 1 // 查找所有非sh文件,-not可换成!
find . -mtime 7 -type f // 搜索最近7天修改过的文件。
//-atime:访问时间 (单位是天,分钟单位则是-amin, -mtime:修改时间(内容被修改),-ctime:变化时间 (元数据或权限变化)
grep - 根据文件内容查找文件¶
grep选项:
| 选项 | 说明 |
|---|---|
| -A | 输出当前匹配内容的后面几行内容 |
| -B | 输入出当前匹配内容的前面几行内容 |
| -C | 输出当前匹配内容的前后几行内容 |
| -r | 递归查找当前目录下的文件的匹配行 |
| -i | 不区分大小的查找当前文件内容 |
| -v | 查找不匹配内容的行 |
| --color | 是否高亮显示匹配的内容,auto-自动,alawys-每次,可以通过环境变量GREP_OPTIONS配置 |
grep -i "hello" hello.php // 在hello.php里面不区分大小写的查找hello
grep -A 3 -i "hello" // 输出成功匹配的行,以及该行之后的三行,-B选项之前
grep -r "hello" dir1/ // 递归查找dir1目录下文件的匹配行
grep --color=always hello hello.php | more // 此时通过more管道时候也会高亮显示
grep --color=always abc file.txt | less -R // 此时通过less管道是也会高亮显示
grep -v php file.txt // 查找不包含php的行
grep -v -e php -e golang file.txt // 查找不包含php和golang的行
6. 归档与备份¶
gzip – 压缩或者展开文件¶
执行gzip命令时,则原始文件的压缩版会替代原始文件。相对应的gunzip程序被用来把压缩文件复原为没有被压缩的版本。
表6.1 giz选项
| 选项 | 说明 |
|---|---|
| -c | 把输出写入到标准输出,并且保留原始文件。也有可能用--stdout 和--to-stdout 选项来指定 |
| -d | 解压缩。正如 gunzip 命令一样。也可以用--decompress 或者--uncompress 选项来指定 |
| -r | 若命令的一个或多个参数是目录,则递归地压缩目录中的文件。也可用--recursive 选项来指定 |
| -t | 测试压缩文件的完整性。也可用--test 选项来指定 |
| -v | 显示压缩过程中的信息。也可用--verbose 选项来指定 |
gzip foo.txt // 压缩foo.txt
ls -l /etc | gzip > foo.txt.gz // 创建了一个目录列表的压缩文件
gzip -d foot.txt.gz // 解压*.gz文件
gzip -tv foo.txt.gz // 测试文件的完整性
gunzip -c foo.txt | less // 不必指定gz拓展名,默认就是
bzip2 - 压缩文件¶
由 Julian Seward 开发,与 gzip 程序相似,但是使用了不同的压缩算法, 舍弃了压缩速度,而实现了更高的压缩级别。在大多数情况下,它的工作模式等同于 gzip。 由 bzip2 压缩的文件,用扩展名 .bz2 来表示
tar - 打包文件¶
在类 Unix 的软件世界中,这个 tar 程序是用来归档文件的经典工具。它的名字,是 tape archive 的简称,揭示了它的根源,它是一款制作磁带备份的工具。而它仍然被用来完成传统任务, 它也同样适用于其它的存储设备。我们经常看到扩展名为 .tar 或者 .tgz 的文件,它们各自表示“普通” 的 tar 包和被 gzip 程序压缩过的 tar 包。一个tar包可以由一组独立的文件,一个或者多个目录,或者 两者混合体组成
表6.2 tar操作模式
| 操作模式 | 说明 |
|---|---|
| -c | 为文件和/或目录列表创建归档文件 |
| -x | 抽取归档文件 |
| -r | 追加具体的路径到归档文件的末尾 |
| -t | 列出归档文件的内容 |
tar -cvf /path/to/foo.tar /path/to/foo/ // 创建一个包
tar -xvf foo.tar // 抽取一个包
tar -czvf /path/to/foo.tgz /path/to/foo/ // 创建.gz归档文件
tar -xzvf /path/to/foo.tgz // 抽取.gz归档文件
tar -ztvf /path/to/foo.tgz // 查看.gz文档文件的文件列表
tar -cjvf /path/to/foo.tgz /path/to/foo/ // 创建.bz2归档文件
tar -xjvf /path/to/foo.tgz // 抽取.bz2归档文件
tar -jtvf /path/to/foo.tgz // 查看.bz2归档文件的文件列表
rsync - 同步目录和文件¶
rsync options source destination
这里 source 和 destination 是下列选项之一: * 一个本地文件或目录 * 一个远端文件或目录,以[user@]host:path 的形式存在 * 一个远端 rsync 服务器,由 rsync://[user@]host[:port]/path 指定
注意 source 和 destination 两者之一必须是本地文件。rsync 不支持远端到远端的复制
rsync -av --delete /etc /home /usr/local /media/BigDisk/backup
// 备份文件到backup目录。--delete来删除可能在备份设备中已经存在但却不再存在于源设备中的文件
rsync -av --delete --rsh=ssh /etc /home /usr/local remote-sys:/backup
// --rsh=ssh 选项,其指示rsync使用ssh程序作为它的远程 shell。
rsync -avzP --progress ~/Documents/static_resource/static/* tinker@10.255.1.174:/wwwroot/static
7. 文本处理¶
cat - 连接文件并输出到标准输出¶
sort - 文本排序¶
表7.1 sort常见选项
| 选项 | 描述 |
|---|---|
| -b | 默认情况下,对整行进行排序,从每行的第一个字符开始。这个选项导致sort程序忽略 每行开头的空格,从第一个非空白字符开始排序 |
| -f | 让排序不区分大小写 |
| -n | 基于数字值大小进行排序,而不是字母值 |
| -r | 按相反顺序排序。结果按照降序排列,而不是升序 |
| -k | -k=field1[,field2],对从field1到field2之间的字符排序,而不是整个文本行。看下面的讨论 |
| -m | 把每个参数看作是一个预先排好序的文件。把多个文件合并成一个排好序的文件,而没有执行额外的排序 |
| -o | 把排好序的输出结果发送到文件,而不是标准输出 |
| -t | 定义域分隔字符。默认情况下,域由空格或制表符分隔 |
sort > foo.txt // 将标准输入内容排序好后存入到foo.txt文件
ls -l /usr/bin | sort -nr -k 5 | head // 将/usr/bin目录下文件按大小排序
sort file1.txt file2.txt file3.txt > final_sorted_list.txt // 合并有序文件
sort -k 1,1 -k 2n -k 3.7n foo.txt
// 多字段排序,对第一个字段执行字母排序,第二个字段执行数值排序,第三个字段的第七个字符按数值排序
sort -t ':' -k 7 /etc/passwd | head // passwd文件的分隔符是:, 按照第七个字段分割
uniq - 显示或省略重复行¶
uniq 只会删除相邻的重复行,常常配合sort使用,排序后然后处理重复行
表7.2 uniq常用选项
| 选项 | 说明 |
|---|---|
| -c | 输出所有的重复行,并且每行开头显示重复的次数 |
| -d | 只输出重复行,而不是特有的文本行 |
| -f n | 忽略每行开头的 n 个字段,字段之间由空格分隔。不同于sort 程序,uniq 没有选项来设置备用的字段分隔符 |
| -i | 在比较文本行的时候忽略大小写 |
| -s n | 跳过(忽略)每行开头的 n 个字符 |
| -u | 只是输出独有的文本行。这是默认的 |
cut - 从每行中删除文本区域¶
表7.3 cut常用选项
| 选项 | 说明 |
|---|---|
| -c char_list | 从文本行中抽取由 char_list 定义的文本。这个列表可能由一个或多个逗号 分隔开的数值区间组成 |
| -f field_list | 从文本行中抽取一个或多个由 field_list 定义的字段。这个列表可能 包括一个或多个字段,或由逗号分隔开的字段区间 |
| -d delim_char | 当指定-f 选项之后,使用 delim_char 做为字段分隔符。默认情况下, 字段之间必须由单个 tab 字符分隔开 |
| --complement | 抽取整个文本行,除了那些由-c 和/或-f 选项指定的文本 |
/* 例如文件a.txt内容格式如下:
tinker:12/07/2017:complete task a
jack:25/09/2017:complete task b
*/
cut -d: -f 2 a.txt | cut -c 7-10 // 输出年份
diff - 逐行比较文件¶
tr - 翻译或删除字符¶
echo "lowercase letters" | tr a-z A-Z // 小写转大写
echo "lowercase letters" | tr [:lower:] [:upper:] // 小写转大写
sed - 文本的流编辑器¶
echo "front" | sed 's/front/back/' // 输出back
sed -n "/string/p" logFile // 打印包含string的行
sed -n '5,10p' /etc/passwd // 查看文件5到10行
sed -n '3,5{=;p}' logFile // 打印3到5行,并且打印行号
sed '/^$/d' file // 删除空行
sed -i "s/原字符串/新字符串/g" `grep 原字符串 -rl 所在目录` // 替换目录下字符串
sed -n '/script_filename =/{n;p}' www.log.slow // 获取匹配行的下一行内容
awk - 文本分析工具¶
awk是超强大的文本分析工具。不仅仅是linux系统中的一个命令,而且是一种编程语言
awk指令是由模式,动作,或者模式和动作的组合组成。awk处理文件按照一行行来处理,默认每行按照空格进行分割
awk使用方法: awk 'pattern { action } '文件 pattern即模式,用来筛选符合一定规则的行 action即动作,用来做相应处理,通常是print

awk '{print $2,$5;}' a.txt // 打印指定的2,5字段
ps aux | grep mysql | grep -v grep |awk '{print $2}' | xargs kill -9 // 杀掉mysql进程
awk '{print $7}' access.log | uniq -c | sort -nr | head -n10 // 访问最多的10个url
cat /proc/meminfo | awk '/^MemTotal/{ers/{j=$0}/^Cached/{k=$0}END{printf("%s\n%s\n%s\n%s\n", h,i,j,k)}' // 查看内存信息
awk -F '[][]' '{print $3}' file // []作为分隔符
awk '$9 > 500 {print $0}' access.log | wc -l // 统计nginx访问日志里面状态码大于等于500的行数
awk -F\" '$2 ~ "^GET /api" {print $0}' access.log // 打印nginx访问日志里面请求方法为GET,url已/api开头的记录
awk '{if(NR>=10 && NR<=20) print $0}' access.log // 打印10到20行
awk '/NR>=10, NR<=20/{print $0}' access.log // 打印10到20行。基于范围模式匹配模式
awk '/script_filename =/{getline a;print a;}' www.log.slow // 获取匹配行的下一行内容。getline是读取下一行内容并复制给变量a,接着打印出来。其中变量a可以省略
head - 显示开头文字行¶
tail¶
vim¶
vim +10 file1.txt // 打开文件并调到第10行
vim +/search_term file2.txt // 打开文件并调到第一个匹配的行
vim -R /etc/passwd // 只读模式打开文件
替换字符用法
语法:[addr]s/源字符串/目的字符串/[option]
:s/vivian/sky/ 替换当前行第一个 vivian 为 sky
:s/vivian/sky/g 替换当前行所有 vivian 为 sky
:n,$s/vivian/sky/g 替换第 n 行开始到最后一行中每一行所有 vivian 为 sky(n 为数字,若 n 为 .,表示从当前行开始到最后一行)
:%s/vivian/sky/(等同于 :g/vivian/s//sky/)替换每一行的第一个 vivian 为 sky
:%s/vivian/sky/g(等同于 :g/vivian/s//sky/g)替换每一行中所有 vivian 为 sky
| 参数 | 说明 |
|---|---|
| [addr] | 表示检索范围,省略时表示当前行。"1,20" :表示从第1行到20行;"%":表示整个文件,同"1,$";". ,$" :从当前行到文件尾; |
| s | 表示替换操作 |
| [option] | 表示操作类型:g 表示全局替换;c 表示进行确认;p 表示替代结果逐行显示(Ctrl + L恢复屏幕);省略option时仅对每行第一个匹配串进行替换;如果在源字符串和目的字符串中出现特殊字符,需要用”\”转义 |
xargs¶
find . -name '*.sh' -maxdepth 1 | xargs -I {} ls '{}' // -I指定替换字符
ls -al | xargs -n 10 rm // 每10做一个分组
find . -name "*.html" -print0 | xargs -0 rm -rf // xargs 默认是以空白字符 (空格,tab,换行符) 做分割,-0表明是使用null字符('')进行分割,可以解决文件名称中出现空格的问题
ls|grep {关键字} | xargs -n 10 rm -fr
wc - 统计行和字符的工具¶
split - 切割文件¶
split用于将文件切割成多个小文件
表7.4 split选项
| 选项 | 说明 |
|---|---|
| b | 每一个新文件的大小,单位为byte |
| C | 每一个文件单行的最大byte数 |
| d | 新文件名以数字作为后缀 |
| l | 每一个新文件的列数大小 |
split -b 10k date.file // 将文件分割成大小为10KB的小文件
split -b 10k date.file -d -a 3 new_file_name // 将文件分割成大小为10KB的小文件, 新文件名以数字作为后缀
split -l 10 date.file // 把文件分割成每个包含10行的小文件
8. 网络管理¶
ping - 发送 ICMP ECHO_REQUEST 软件包到网络主机¶
ping 命令发送一个特殊的网络数据包,叫做IMCP ECHO_REQUEST,到 一台指定的主机。大多数接收这个包的网络设备将会回复它,来允许网络连接验证,反应连接速度。
注意:大多数网络设备(包括 Linux 主机)都可以被配置为忽略这些数据包。通常,这样做是出于网络安全 原因,部分地遮蔽一台主机免受一个潜在攻击者地侵袭。配置防火墙来阻塞IMCP流量也很普遍。
traceroute - 打印到一台网络主机的路由数据包¶
显示从本地到指定主机 要经过的所有路由
traceroute www.cyub.vip
netstat - 网络查看工具¶
表7.5 netstat常见选项
| 选项 | 说明 |
|---|---|
| a | 显示所有连线中的Socket |
| l | 显示监控中的服务器的Socket |
| n | 直接使用ip地址,而不通过域名服务器 |
| p | 显示正在使用Socket的程序识别码和程序名称 |
| r | 显示Routing Table |
| t | 显示TCP传输协议的连线状况 |
| u | 显示UDP传输协议的连线状况 |
| e | 显示网络其他相关信息 |
| i | 显示网络界面信息表单 |
| o | 显示计时器 |
netstat -ie // 查看系统网络接口
netstat -nr // 查看路由
netstat -an|awk '/^tcp/{++S[$NF]}END{for (a in S)print a,S[a]}' // 查看tcp链接数
netstat -pant |grep ":80"|awk '{print $5}' | awk -F: '{print $1}'|sort|uniq -c|sort -nr // 查看连接数最多的ip
netstat -tunlp | grep 22 // 查看22端口情况
sudo netstat -pnt | grep :80 | wc -l // 粗略估计访问80端口人数
ftp - 因特网文件传输程序¶
wget - 非交互式网络下载器¶
ssh - SSH 客户端¶
nslookup - 查看dns解析¶
dig - 查看dns解析¶
dig www.cyub.vip a // 查询域名的A记录,最后的a可省略
dig www.cyub.vip mx // 查询域名的mx记录,其他类型的记录有MX,CNAME,NS,PTR等,默认a记录
dig @10.255.1.174 www.cyub.vip // 指定dns服务器
dig www.cyub.vip a +tcp // dig默认使用udp协议进行查询,+tcp参数则指定tcp方式查询
dig www.cyub.vip a +trace // +trace参数将显示从根域逐级查询的过程
curl - 传输数据工具¶
curl www.cyub.vip // 查看网页内容
curl -s -o cyub.me.txt www.cyub.vip // 保存网页内容, -s表示silent,不会显示下载进度
curl -O --progress -C www.cyub.vip/file.zip // 下载文件,本地文件名称与远程服务器文件名称一样。--progress显示进度条,-C继续断点下载
curl --head(I) www.cyub.vip // 查看网页响应头
curl --data(d) "birthyear=1905&press=%20OK%20" www.cyub.vip // 以Content-Type=application/x-www-form-urlencoded形式
// POST数据,此时的数据需要urlencode处理好
curl --data-urlencode "name=I am Daniel" www.cyub.vip // 跟上一条命令类似,但数据不用预先编码处理
curl --form upload=@localfilename --form press=OK www.cyub.vip // 文件上传,Content-Type是multipart/form-data
curl --proxy proxy.cyub.vip:4321 www.cyub.vip/ // 设置代理
curl --user name:password www.cyub.vip // Basic Authentication
curl --cookie "name=tinker" www.cyub.vip // cookie
curl --dump-header headers_and_cookies www.cyub.vip
curl --header(H) "Content-Type: text/xml" --request www.cyub.vip
curl --request(X) POST www.cyub.vip // 指定请求方法
curl -v www.cyub.vip // 显示通信过程
curl --trace output.txt www.cyub.vip // 显示通信过程,内容比上一条命令详细
curl --trace-ascii dump.txt www.cyub.vip // 显示通信过程
curl还可以通过设置-w选项的时间变量来查看具体传输请求时间,常用变量如下:
| 选项 | 说明 |
|---|---|
| content_type | 请求文件的Content-Type |
| http_code | 响应状态码 |
| http_version | http版本 |
| local_ip | local ip |
| local_port | local port |
| redirect_url | 当请求没有指定-L, --location来保存重定向时候, 此变量显示重定向url |
| remote_ip | remote IP |
| remote_port | remote port |
| scheme | URL scheme |
| size_download | 请求文件的大小(单位byte) |
| size_header | 响应头的大小(单位byte) |
| speed_download | 平均下载速度(单位byte/s) |
| time_appconnect | SSL/SSH 3次握手完成时间(单位s) |
| time_connect | 与远程服务器建立连接完成时间(单位s) |
| time_namelookup | 从请求开始到DNS解析完毕所用时间(单位s) |
| time_starttransfer | 最初的网络请求被发起到从服务器接收到第一个字节前所花费时间,即TTFB(单位s) |
| time_total | 完成请求总共时间(单位s) |
注意: 某些变量高版本curl才支持, 具体参见curl man page
用法如下:
curl -o /dev/null -s -w %{http_code}:%{remote_ip}:%{time_total} http://www.cyub.vip
// 把变量写入curl-format.txt文件里面
curl -o /dev/null -s -w "@curl-format.txt" http://www.cyub.vip
// curl-format.txt
response_code: %{http_code} %{content_type}\n
client_server: %{local_ip}:%{local_port} => %{remote_ip}:%{remote_port}\n
dns_resolution: %{time_namelookup}s\n
tcp_established: %{time_connect}s\n
ssl_handshake_done: %{time_appconnect}s\n
TTFB: %{time_starttransfer}s\n
time_total: %{time_total}s\n
size_download: %{size_download}bytes\n
speed_download: %{speed_download}byte/s\n
tcpdump - 网络流量监测工具¶
tcpdump默认抓取68个字节。
tcpdump -i eth0 not port 22 // 查看eth0接口非22端口的流量
tcpdump -i eth0 -s 0 -w file.cap // 保存抓包信息到文件中
Tcpdump -r file.pcap // 读取抓包文件
tcpdump -A -r file.pcap // 以ascii吗形式显示包内容
firewall-cmd - 防火墙管理¶
FirewallD 是 iptables 的前端控制器,用于实现持久的网络流量规则。它提供命令行和图形界面
防火墙启动与关闭
systemctl start firewalld // 启动防火墙
systemctl enable firewalld // 设置开机启动
systemctl stop firewalld // 关闭防火墙
systemctl disable firewalld // 设置不开机启动
firewall-cmd用例
firewall-cmd --zone=public --add-port=80/tcp --permanent // 开放80端口
firewall-cmd --reload // 重新加载防火墙配置
firewall-cmd --state // 查看防火墙状态
firewall-cmd --get-zones // 列出支持的zone
firewall-cmd --get-services // 列出支持的服务,在列表中的服务是放行的
firewall-cmd --query-service ftp // 查看ftp服务是否支持,返回yes或者no
firewall-cmd --add-service=ftp // 临时开放ftp服务
firewall-cmd --add-service=ftp --permanent // 永久开放ftp服务
firewall-cmd --remove-service=ftp --permanent // 永久移除ftp服务
ifconfig¶
sftp¶
scp¶
nc - 网络工具中的瑞士军刀¶
nc是netcat命令别名
表7.6 nc常见选项
| 选项 | 说明 |
|---|---|
| s | 本地源ip |
| p | 进行远程连接的本地端口 |
| l | 监听模式 |
| u | udp 模式 |
| v | 显示详细 |
| w | 超时时间 |
| z | 用于扫描的Zero-I/O模式 |
| n | 直接使用ip 不使用DNS反向查询IP地址的域名 |
// 扫描192.168.33.10的20至25的端口
nc -nzv 192.168.33.10 20-25
// 使用10.1.2.3作为源地址,31337作为源端口,连接host.example.com的42端口,超时时间设为5秒
nc -s 10.1.2.3 -p 31337 -w 5 host.example.com 42
// 模拟http请求, 注意最后面需要两个换行
nc www.cyub.vip 80 '
GET / HTTP/1.1
Host: www.cyub.vip
User-Agent: self-browser
'
或者
nc www.cyub.vip 80 < request.text > index.html
// 使用HTTP proxy代理10.2.3.4:8080连接host.example.com
nc -x10.2.3.4:8080 -Xconnect host.example.com 42
// 创建和监听UNIX-domain stream socket
nc -lU /var/tmp/dsocket
9. 系统监控¶
uptime¶
htop¶
iotop¶
vmstat - 显示资源使用快照¶
显示资源快照,包括内存,交换分区和磁盘 I/O
vmstat 1 // 1秒内的资源快照
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 488124 105284 96596 429796 0 1 4 6 23 12 0 0 99 0 0
0 0 488124 105160 96596 429796 0 0 0 0 280 554 0 1 99 0 0
0 0 488124 105160 96596 429804 0 0 0 0 260 544 1 0 99 0 0
0 0 488124 105160 96596 429796 0 0 0 0 254 539 0 1 99 0 0
0 0 488124 105160 96596 429804 0 0 0 0 268 550 0 1 99 0 0
0 0 488124 105160 96600 429792 0 0 0 64 680 1456 2 3 95 0 0
1 0 488112 96972 96608 429812 0 0 0 40 824 1393 31 4 65 0 0
0 0 488112 96880 96608 429804 0 0 0 0 269 566 0 0 100 0 0
说明:
| 项 | 列 | 含义 |
|---|---|---|
| procs | r | 运行队列中进程数量,如果长期大于1,说明cpu不足,需要增加cpu |
| b | 等待IO的进程数量 | |
| memory | swpd | 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能 |
| free | 空闲物理内存大小(单位k) | |
| buff | 用作缓冲的内存大小 | |
| cache | 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小 | |
| system | in | 表示在某一时间间隔中观测到的每秒设备中断数 |
| cs | 表表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查 | |
| swap | si | 由内存进入内存交换区数量 |
| so | 由内存交换区进入内存数量 | |
| io | bi | 每秒读取的块数(默认块的大小为1kb) |
| bo | 每秒写入的块数 | |
| cpu | us | 显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序 |
| sy | 显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy大于80%说明可能存在CPU不足 | |
| id | 显示了cpu处在空闲状态的时间百分比 | |
| wa | 显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。 |
iostat - 监视系统输入输出设备和CPU的使用情况¶
常用选项:
| 选项 | 说明 |
|---|---|
| -c | 仅显示CPU使用情况 |
| -d | 仅显示设备利用率 |
| -k | 显示状态以千字节每秒为单位,而不使用块每秒 |
| -m | 显示状态以兆字节每秒为单位 |
| -p | 仅显示块设备和所有被使用的其他分区的状态 |
| -t | 显示每个报告产生时的时间 |
| -x | 显示扩展状态 |
iostat -x
Linux 4.4.0-101-generic (vagrant) 02/10/2018 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.20 0.01 0.29 0.03 0.00 99.48
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.02 0.73 0.24 0.78 3.76 6.20 19.47 0.00 0.45 0.62 0.40 0.33 0.03
dm-0 0.00 0.00 0.22 1.18 3.55 5.39 12.77 0.00 0.44 0.60 0.42 0.24 0.03
dm-1 0.00 0.00 0.04 0.20 0.15 0.81 8.03 0.00 5.62 0.51 6.57 0.05 0.00
说明
| 标示 | 说明 |
|---|---|
| Device | 监测设备名称 |
| rrqm/s | 每秒需要读取需求的数量 |
| wrqm/s | 每秒需要写入需求的数量 |
| r/s | 每秒实际读取需求的数量 |
| w/s | 每秒实际写入需求的数量 |
| rsec/s | 每秒读取区段的数量 |
| wsec/s | 每秒写入区段的数量 |
| rkB/s | 每秒实际读取的大小,单位为KB |
| wkB/s | 每秒实际写入的大小,单位为KB |
| avgrq-sz | 需求的平均大小区段 |
| avgqu-sz | 需求的平均队列长度 |
| await | 等待I/O平均的时间(milliseconds) |
| svctm | I/O需求完成的平均时间 |
| %util | 被I/O需求消耗的CPU百分比 |
systemctl - 系统服务管理¶
systemctl是系统服务管理命令,它实际上将service和chkconfig这两个命令组合到一起。
| 任务 | 旧指令 | 新指令 |
|---|---|---|
| 使某服务自动启动 | chkconfig --level 3 httpd on | systemctl enable httpd.service |
| 使某服务不自动启动 | chkconfig --level 3 httpd off | systemctl disable httpd.service |
| 检查服务状态 | service httpd status | systemctl status httpd.service 服务详细信息 systemctl is-active httpd.service 仅显示是否Active |
| 显示所有已启动的服务 | chkconfig --list | systemctl list-units --type=service |
| 启动某服务 | service httpd start | systemctl start httpd.service |
| 停止某服务 | service httpd stop | systemctl stop httpd.service |
| 重启某服务 | service httpd restart | systemctl restart httpd.service |
systemctl start nfs-server.service // 启动nfs服务
systemctl enable nfs-server.service // 设置开机自启动
systemctl disable nfs-server.service // 停止开机自启动
systemctl status nfs-server.service // 查看服务当前状态
systemctl restart nfs-server.service // 重新启动某服务
systemctl list -units --type=service // 查看所有已启动的服务
systemctl list-dependencies nfs-server // 列出服务的依赖
lsof - 一切皆文件¶
lsof(list open files)是一个查看当前系统文件的工具。 在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。 如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,该文件描述符提供了大量关于这个应用程序本身的信息。
lsof /var/log/nginx/access.log // 查看哪个进程打开access.log
lsof -p `pgrep redis` // 查看进程打开的文件,参数是pid
lsof -c php-fpm7 // 查看进程打开的文件,参数是进程名称
lsof -u vagrant // 查看用户打开的文件
lsof -i:80 // 查看哪个进程监听80端口
lsof -i4 // 列出ipv4相关信息
lsof -d 1 // 列出占用文件描述符1的进程
lsof -d /tmp // 列出/tmp目录下被打开的文件
lsof -D /tmp // 递归列出/tmp目录下被打开的文件
free¶
df¶
shutdown - 系统关机¶
watch - 定时监控命令¶
strace - 跟踪程序执行¶
strace命令是一个集诊断、调试、统计与一体的工具
表9.1 strace常用选项
| 选项 | 说明 |
|---|---|
| -p | 指定跟踪进程的pid |
| -c | 统计每一系统调用的所执行的时间,次数和出错的次数等 |
| -f | 跟踪由fork调用所产生的子进程 |
| -ff | 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号 |
| -t | 在输出中的每一行前加上时间信息. -tt 在输出中的每一行前加上时间信息,微秒级 |
| -T | 显示每一调用所耗的时间,每个调用的时间花销现在在调用行最右边的尖括号里面 |
| -o | 将strace的输出写入文件filename,如果不指定-o参数的话,默认的输出设备是STDERR |
| -e | 指定一个表达式,用来控制如何跟踪。格式:[qualifier=][!]value1[,value2]... qualifier只能是trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open 表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none. 注意有些shell使用!来执行历史记录里的命令,所以要使用\. |
-e选项常用正则如下: 默认的为trace=all. + -e trace=file 只跟踪有关文件操作的系统调用. + -e trace=process 只跟踪有关进程控制的系统调用. + -e trace=network 跟踪与网络有关的所有系统调用. + -e strace=signal 跟踪所有与系统信号有关的系统调用 + -e trace=ipc 跟踪所有与进程通讯有关的系统调用
strace -e open,access 2>&1 | grep your-filename // 查看打开文件情况
strace -e open php 2>&1 | grep php.ini // 查看php加载php.ini信息
strace -c >/dev/null ls // 跟踪ls命令执行情况
strace -f $(pidof php-fpm | sed 's/\([0-9]*\)/\-p \1/g') // 查看php-fpm进程情况
strace -f -tt -o /tmp/php.trace -s1024 -p `pidof php5-fpm | tr ' ' ','` // 同上
10. 其他¶
ulimit¶
linux 默认值 open files 和 max user processes 为 1024
uname¶
timedatectl - 查看和设置时间¶
timedatectl是用来查询和修改系统时间和配置的Linux应用程序。它是systemd 系统服务管理的一部分,并且允许你检查和修改系统时钟的配置。
timedatectl // 查看当前时间和时区
timedatectl set-time YYYY-MM-DD // 设置日期
timedatectl set-time HH:MM:SS // 设置时间
timedatectl list-timezones // 查看所有时区
timedatectl set-timezone 'Asia/Shanghai' // 设置时区
timedatectl set-ntp yes // 设置NTP同步,使用“no”关闭NTP同步,使用“yes”开启
nice¶
ssh-keygen¶
openssl¶
date¶
快捷键¶
| 快捷键 | 说明 |
|---|---|
| ctrl + u | 删除从开头到光标处的命令文本 |
| ctrl + k | 删除从光标到结尾处的命令文本 |
| ctrl + a | 光标移动到命令开头 |
| ctrl + e | 光标移动到命令结尾 |
| ctrl + w | 删除一个词(以空格隔开的字符串) |
| ctrl + c | 中断程序执行(产生SIGINT信号) |
| ctrl + \ | 退出程序执行(产生SIGQUIT信号) |
| ctrl + d | 默认的文件结束符 |
| ctrl + insert | 复制 |
| shift + insert | 黏贴 |
| ctrl + s | 冻结屏幕 |
| ctrl + q | 退出冻结屏幕 |