概览¶
为什么说ES是准实时的?¶
术语¶
| 术语 | 解释 |
|---|---|
| Lucene | Elasticsearch所基于的 Java 库,它引入了按段搜索的概念 |
| Segment | 也叫段,类似于倒排索引,相当于一个数据集 |
| Commit point | 提交点,记录着所有已知的段 |
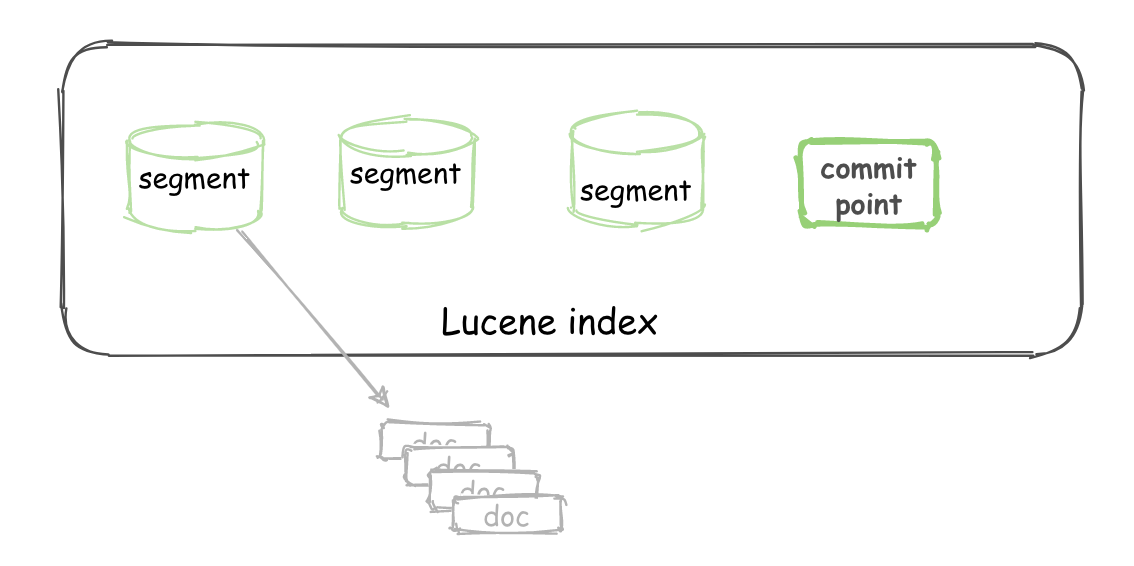
| Lucene index | “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一个提交点组成 |
对于一个 Lucene index 的组成,如下图所示:
一个 Elasticsearch Index 由一个或者多个 shard (分片) 组成,而 Lucene 中的 Lucene index 相当于 ES 的一个 shard:
写入过程¶
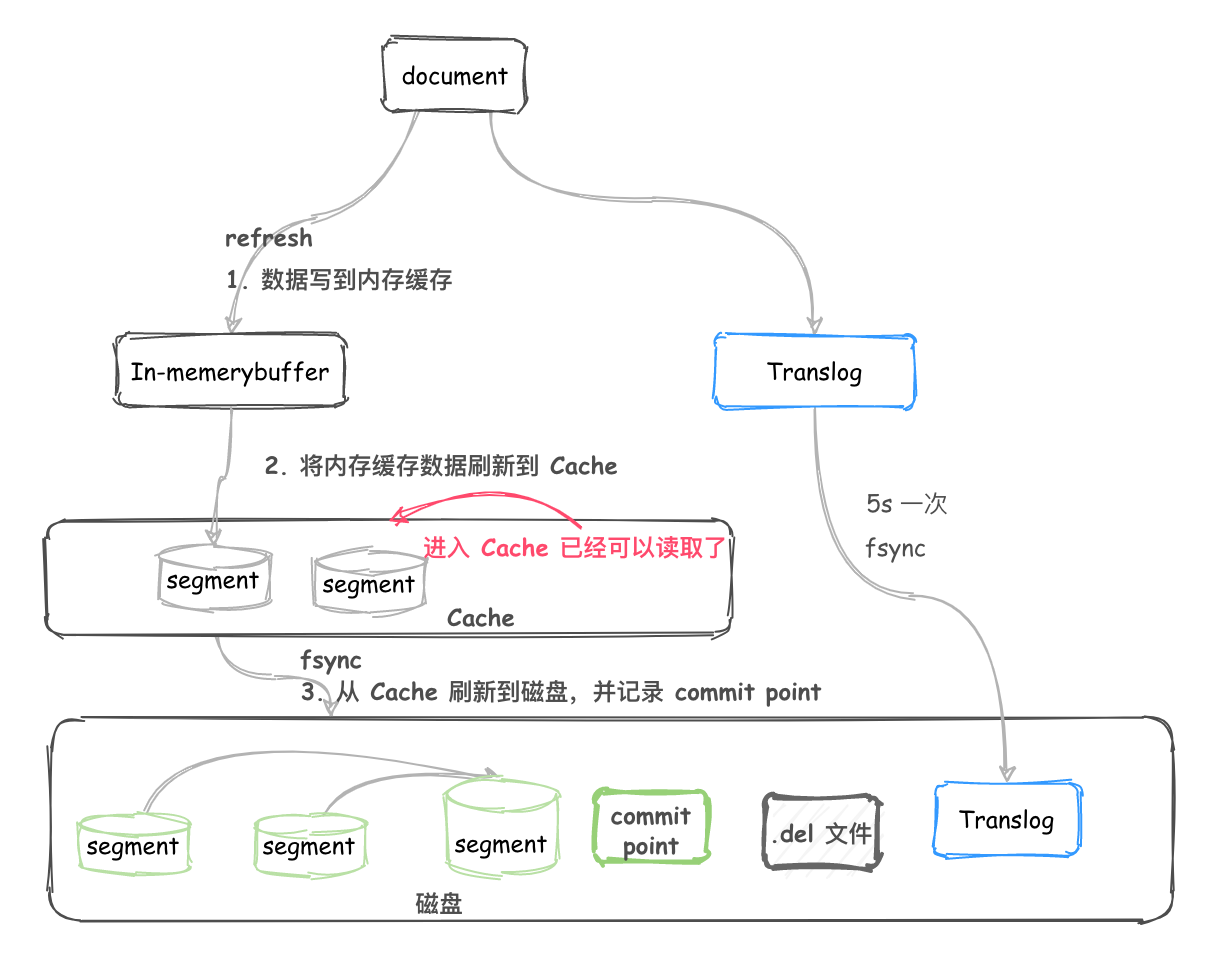
- Document 不断写入到 Indexing buffer,此时也会追加 translog。
- 当 buffer 中的数据每隔
index.refresh_interval秒(或者Indexing buffer满了)缓存refresh到 cache 中时,此时文档是可以检索到了(这也就是为什么说 Elasticsearch 是准实时的)。translog 并没有进入到刷新到磁盘,是持续追加的。 - translog 每隔
index.translog.interval秒会检查translog是否符合flush条件, 如果符合则fsync 到磁盘。
随着translog文件越来越大时要考虑把内存中的数据刷新到磁盘中,这个过程称为flush,flush过程主要做了如下操作:
- 把所有在内存缓冲区中的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 文件系统的page cache(segments) fsync到磁盘
- 删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了
ES translog关键配置参数,更多参数见translog参数:
-
index.translog.sync_interval
控制translog多久fsync到磁盘,最小为100ms,默认为5s - index.translog.durability 是每隔
index.translog.sync_interval刷新一次还是每次请求都fsync - request - 每次请求都进行fsync,默认值 - async - 每隔sync_interval都会检查translog大小,判断是否需要fsync - index.translog.flush_threshold_sizetranslog的大小超过这个参数后会flush,默认512mb
删除和更新¶
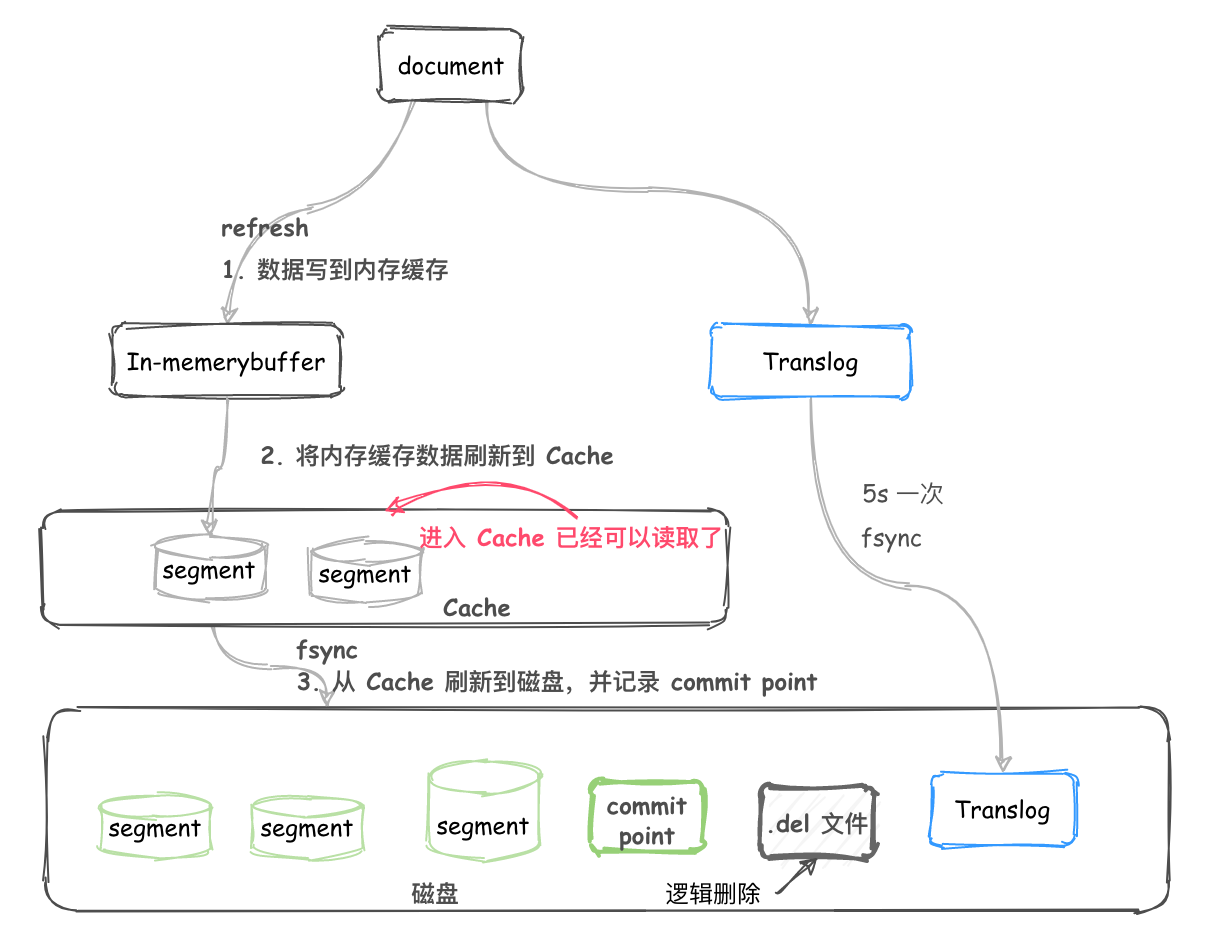
segment 不可改变,所以 docment 并不能从之前的 segment 中移除或更新。
所以每次 commit, 生成 commit point 时,会有一个 .del 文件,里面会列出被删除的 document(逻辑删除)。
而查询时,获取到的结果在返回前会经过 .del 过滤。更新时,也会标记旧的 docment 被删除,写入到 .del 文件,同时会写入一个新的文件。此时查询会查询到两个版本的数据,但在返回前会被移除掉一个。
segment 合并¶
每 1s 执行一次 refresh 都会将内存中的数据创建一个 segment。 segment 数目太多会带来较大的麻烦。 每一个 segment 都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个 segment ;所以 segment 越多,搜索也就越慢。
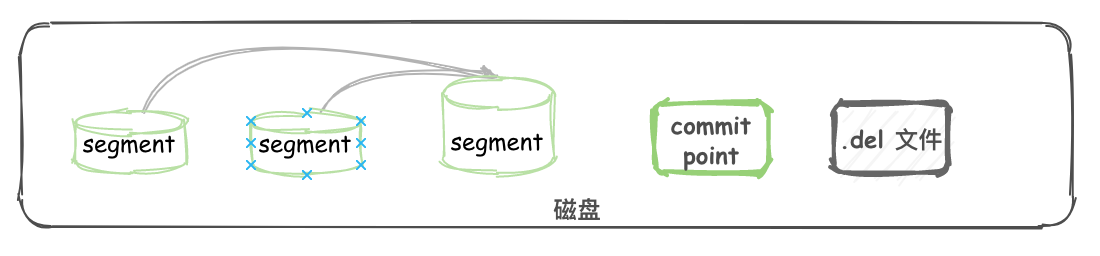
在 segment merge 这块,那些被逻辑删除的 document 才会被真正的物理删除。
在 ES 后台会有一个线程进行 segment 合并:
- refresh操作会创建新的 segment 并打开以供搜索使用。
- 合并进程选择一小部分大小相似的 segment,并且在后台将它们合并到更大的 segment 中。这并不会中断索引和搜索。
- 当合并结束,老的 segment 被删除 说明合并完成时的活动:
- 新的 segment 被刷新(flush)到了磁盘。 写入一个包含新 segment 且排除旧的和较小的 segment的新 commit point。
- 新的 segment 被打开用来搜索。
- 老的 segment 被删除。
ElasticSearch 性能调优¶
- https://blog.csdn.net/alex_xfboy/article/details/87938810
- https://hiddenpps.blog.csdn.net/article/details/99145672
- https://blog.csdn.net/laoyang360/article/details/100070285
- https://learnku.com/articles/41631
- https://learnku.com/articles/40845
- https://learnku.com/articles/40099
- https://learnku.com/articles/40844
- https://blog.csdn.net/wmj2004/article/details/80804411
Circuit Breaker¶
ES中包含多种断路器,避免不合理操作引发的 OOM,每个断路器可以指定内存使用的限制 - Parent circuit breaker:设置所有的熔断器可以使用的内存的总量 - Fielddata circuit breaker:加载 fielddata 所需要的内存 - Request circuit breaker:防止每个请求级数据结构超过一定的内存(例如聚合计算的内存) - In flight circuit breaker:Request 中的断路器 - Accounting request circuit breaker:请求结束后不能释放的对象所占用的内存
Circuit Breaker 统计信息:
- Tripped 大于 0, 说明有过熔断 - Limit size 与 estimated size 约接近,越可能引发熔断Search Type¶
查询时候通过设置search_type参数来设置搜索类型。
-
- 向每一个分片发送查询请求
- 在每一个分片上查询符合要求的数据,并且根据当前分片的 TF 和 DF 计算相关性得分
- 构建一个优先级队列存储查询结果(包含分页、排序,等等)
- 把查询结果的 metadata 返回给协调节点。注意真正的文档此时还并没有返回,返回的只是得分数据和对应的文档ID
- 协调节点对从所有分片上返回的得分数据进行归并和排序,根据查询标准对得分数据进行选择
- 最终所有符合查询要求的文档被从其所在的分片上取回到协调节点
- 协调节点将数据返回给客户端
- Dfs, Query Then Fetch
- 预查询所有的分片,得到一个索引中全局的 Term 和 Document 的频率信息
- 向每一个分片发送查询请求,在每一个分片上查询符合要求的数据,并根据全局的 Term 和 Document 的频率信息计算相关性得分
- 构建一个优先级队列存储查询结果(包含分页、排序,等等)
- 把查询结果的 metadata 返回给协调节点。注意,真正的文档此时还并没有返回,返回的只是得分数据
- 协调节点对从所有分片上返回的得分数据进行归并和排序,根据查询标准对得分数据进行选择
- 最终所有符合查询要求的文档被从其所在的分片上取回到协调节点
- 协调节点将数据返回给客户端
深度分页问题¶
我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因。
Doc Values & Field Data¶
- https://learnku.com/articles/38499
- https://blog.csdn.net/thomas0yang/article/details/64905926
- cat api