FAQ
FAQ¶
为什么用自增列作为主键?¶
-
如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引。
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
-
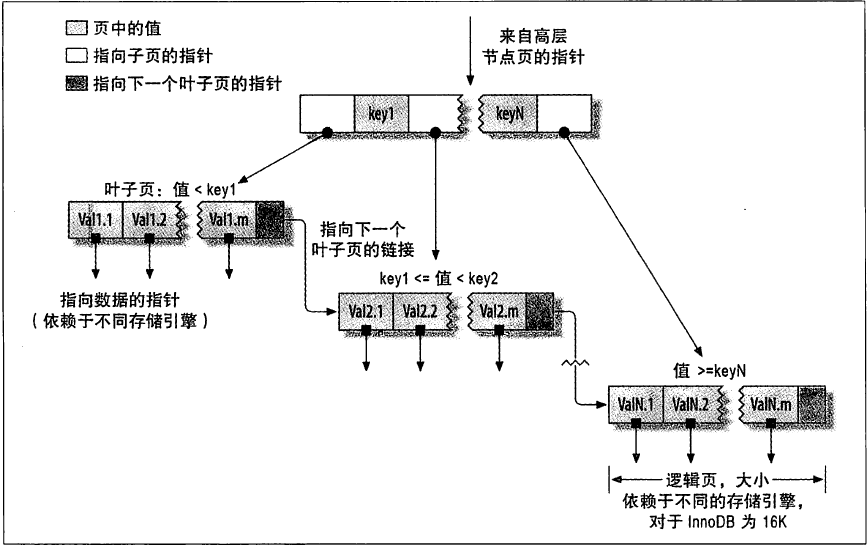
数据记录本身被存于主索引(一颗B+Tree)的叶子节点上,这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放
因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
-
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页(这样的页称为叶子页)
-
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新记录都要被插到现有索引页得中间某个位置
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销
同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
查看inodb叶子页大小可以通过:
为什么使用数据索引能提高效率?¶
-
数据索引的存储是有序的
-
在有序的情况下,通过索引查询一个数据是无需遍历索引记录的
-
极端情况下,数据索引的查询效率为二分法查询效率,趋近于 log2(N)
B+树索引和哈希索引的区别¶
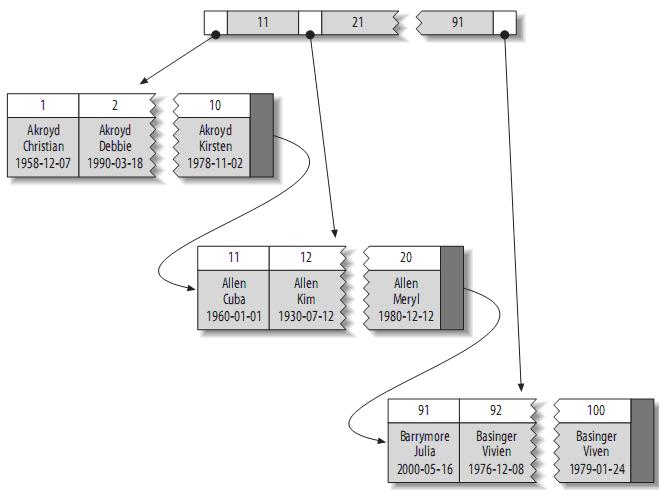
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接,是有序的,如下图:
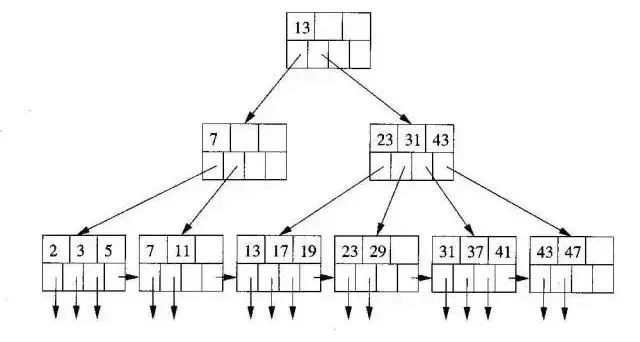
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的,如下图所示:
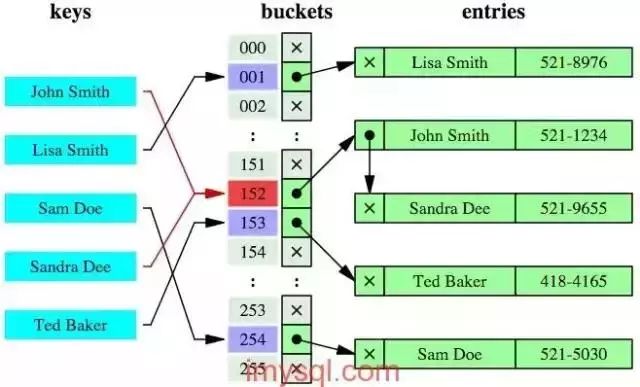
哈希索引的优势与劣势:¶
等值查询,哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
不支持范围查询
不支持索引完成排序
不支持联合索引的最左前缀匹配规则
通常,B+树索引结构适用于绝大多数场景,像下面这种场景用哈希索引才更有优势:
在HEAP表中,如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引,例如这种SQL:
B树和B+树的区别¶
B树,每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为nul,叶子结点不包含任何关键字信息。
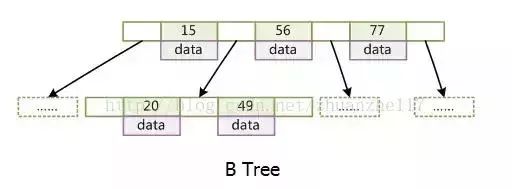
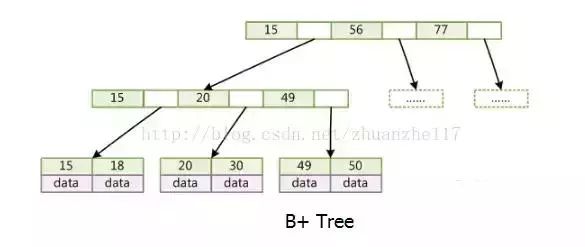
B+树,所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?¶
- B+的磁盘读写代价更低。
B+的内部结点并没有指向关键字具体信息的指针,因此其内部结点相对B树更小。
如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
- B+ tree的查询效率更加稳定。
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
什么情况下应不建或少建索引?¶
-
表记录太少
-
经常插入、删除、修改的表
-
数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
-
经常和主字段一块查询但主字段索引值比较多的表字段
什么是表分区?¶
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
表分区与分表的区别¶
分表: 指的是通过一定规则,将一张表分解成多张不同的表。比如将用户订单记录根据时间成多个表。
分表与分区的区别在于: 分区从逻辑上来讲只有一张表,而分表则是将一张表分解成多张表。
表分区有什么好处?¶
-
存储更多数据。分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。和单个磁盘或者文件系统相比,可以存储更多数据
-
优化查询。在where语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
-
分区表更容易维护。例如:想批量删除大量数据可以清除整个分区。
-
避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3问价你系统的inode锁竞争等。
分区表的限制因素¶
-
一个表最多只能有1024个分区
-
MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中提供了非整数表达式分区的支持。
-
如果分区字段中有主键或者唯一索引的列,那么多有主键列和唯一索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
-
分区表中无法使用外键约束
-
MySQL的分区适用于一个表的所有数据和索引,不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表分区,也不能只对表的一部分数据分区。
如何判断当前MySQL是否支持分区?¶
命令:show variables like '%partition%' 运行结果:
have_partintioning 的值为YES,表示支持分区。
MySQL支持的分区类型有哪些?¶
-
RANGE分区: 这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区
-
LIST分区: 这种模式允许系统通过预定义的列表的值来对数据进行分割。按照List中的值分区,与RANGE的区别是,range分区的区间范围值是连续的。
-
HASH分区 :这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
-
KEY分区 :上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
四种隔离级别¶
-
Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
-
Repeatable read (可重复读):可避免脏读、不可重复读的发生。
-
Read committed (读已提交):可避免脏读的发生。
-
Read uncommitted (读未提交):最低级别,任何情况都无法保证。
关于MVVC¶
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control)
注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control
MVCC最大的好处:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,现阶段几乎所有的RDBMS,都支持了MVCC。
-
LBCC:Lock-Based Concurrency Control,基于锁的并发控制
-
MVCC:Multi-Version Concurrency Control
基于多版本的并发控制协议。纯粹基于锁的并发机制并发量低,MVCC是在基于锁的并发控制上的改进,主要是在读操作上提高了并发量。
在MVCC并发控制中,读操作可以分成两类:¶
快照读 (snapshot read):读取的是记录的可见版本 (有可能是历史版本),不用加锁(共享读锁s锁也不加,所以不会阻塞其他事务的写)
当前读 (current read):读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录
行级锁定的优点:¶
1、当在许多线程中访问不同的行时只存在少量锁定冲突。
2、回滚时只有少量的更改
3、可以长时间锁定单一的行。
行级锁定的缺点:¶
比页级或表级锁定占用更多的内存。
当在表的大部分中使用时,比页级或表级锁定速度慢,因为你必须获取更多的锁。
如果你在大部分数据上经常进行GROUP BY操作或者必须经常扫描整个表,比其它锁定明显慢很多。
用高级别锁定,通过支持不同的类型锁定,你也可以很容易地调节应用程序,因为其锁成本小于行级锁定。
MySQL优化¶
-
开启查询缓存,优化查询
-
explain你的select查询,这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的
-
当只要一行数据时使用limit 1,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据
-
为搜索字段建索引
-
使用 ENUM 而不是 VARCHAR。如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是VARCHAR
-
Prepared StatementsPrepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。
Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击
-
垂直分表
-
选择正确的存储引擎
Mysql 中 MyISAM 和 InnoDB 的区别有哪些?¶
区别:
-
InnoDB支持事务,MyISAM不支持
-
对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
-
InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。
但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此主键不应该过大,因为主键太大,其他索引也都会很大。
而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
-
InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
-
Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
如何选择:
是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB
系统奔溃后,MyISAM恢复起来更困难,能否接受;
MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。