IO¶
Page Cache是怎么回事?¶
Page cache是通过将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,从而提高性能,这个内存就是Page Cache。Page Cache中被修改的内存页称之为脏页(Dirty Page),脏页在特定的时候被一个叫做pdflush(Page Dirty Flush)的内核线程写入磁盘。
Page Cache中写入方式称为Write back(写回),属于异步方式,即写入内存中即返回,它属于buffered I/O。若写入磁盘之后才返回就是Write Through(写穿),它属于direct I/O。
Page Cache缺点就是会导致数据丢失。为了解决这个问题可以使用WAL技术(Write-Ahead Log),在数据库中一般又称之为redo log。WAL日志是append模式,写入速度是O(1)。
Page Cache与mmap(memory-maped I/O)区别:
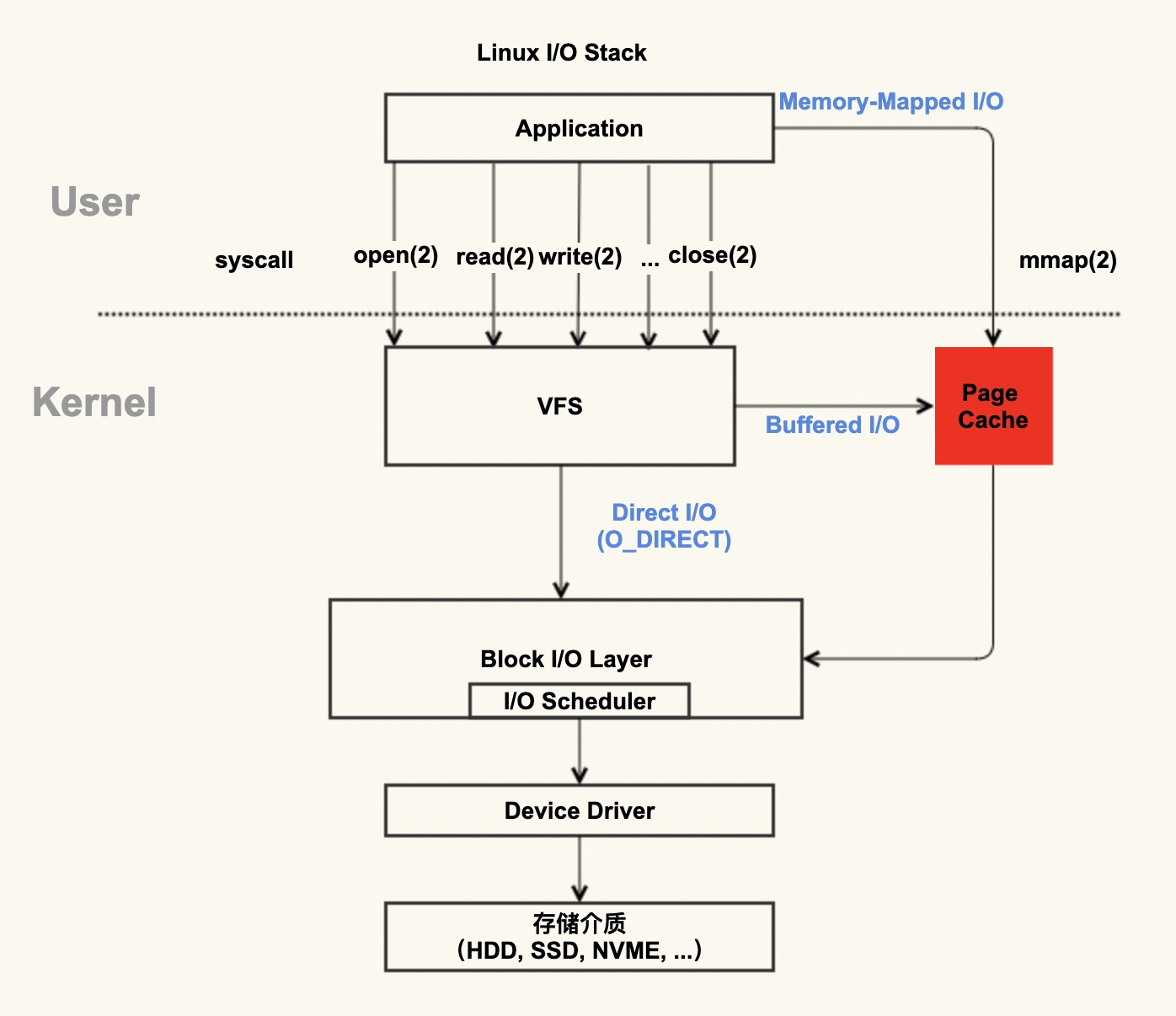
mmap是怎么回事?¶
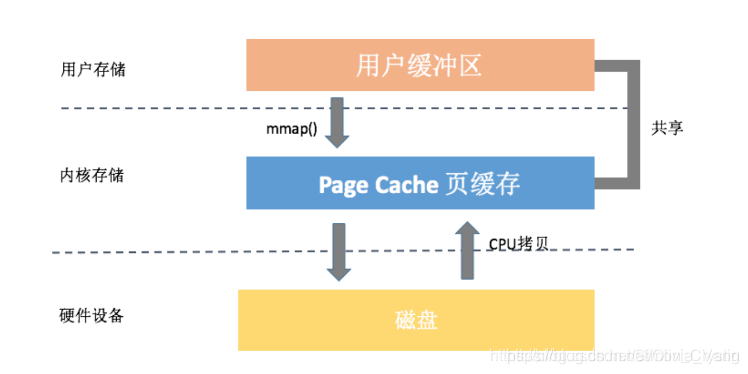
Page Cache的写入时候,需要从应用缓冲区拷贝到内核缓冲区(即Page Cache)。为了避免这样,可以使用mmap技术。
mmap 把文件映射到用户空间里的虚拟地址空间,实现文件和进程虚拟地址空间中一段虚拟地址的一一对映关系。它省去了从内核缓冲区复制到用户空间的过程,进程就可以采用指针的方式读写操作这一段内存(文件 / page cache)。而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作。相反,内核空间对这段区域的修改也直接反映到用户空间,从而可以实现用户态和内核态对此内存区域的共享。
但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作,只有真正使用这些数据时,虚拟内存管理系统 VMS 才根据缺页加载的机制从磁盘加载对应的数据块到内核态的Page Cache。这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高。
mmap有以下特点:
- 文件(page cache)直接映射到用户虚拟地址空间,内核态和用户态共享一片page cache,避免了一次数据拷贝
- 建立mmap之后,并不会立马加载数据到内存,只有真正使用数据时,才会引发缺页异常并加载数据到内存
网络IO模型有哪些?¶
阻塞I/O¶
从发起系统调用(比如read)时候,从等待数据到复制到内核和从内核复制到用户态,全程阻塞。
非阻塞I/O¶
从发起系统调用之后,无需等待,通过轮询方式获取状态,数据准备阶段是fe非阻塞的,而从内核拷贝到用户空间是阻塞的
I/O多路复用¶
监听多个IO对象,当IO对象有数据时候,通知用户进程。
异步I/O¶
发起系统调用后等待数据到达和数据从内核复制到用户态两个io阶段都是非阻塞的
I/O多路复用中select/poll/epoll的区别?¶
select/poll属于一类,传给一组文件描述符数组,返回准备就绪的文件描述符数组,select有大小限制(1024),poll则没有,他们每次都要传文件描述符数组,比较低效,epoll在内核开辟一个空间存放描述符,无须频繁的从用户空间传递给内核
僵尸进程与孤儿进程区别?¶
僵尸进程指的子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,那么子进程的状态描述符依然保存在系统中。此时子进程将成为一个僵尸进程,解决办法是父进程用wait或者waitpid来获取子进程的状态信息,
孤儿进程指的是一个父进程退出, 而它的一个或几个子进程仍然还在运行,那么这些子进程就会变成孤儿进程,孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集的工作
多进程通信方式有哪些?¶
- 共享内存
- 消息队列
- 信号
- 管道
- socket