消息队列¶
为什么要使用消息队列?¶
- 业务解耦
- 异步处理
- 流量削峰
kafka是什么?¶
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
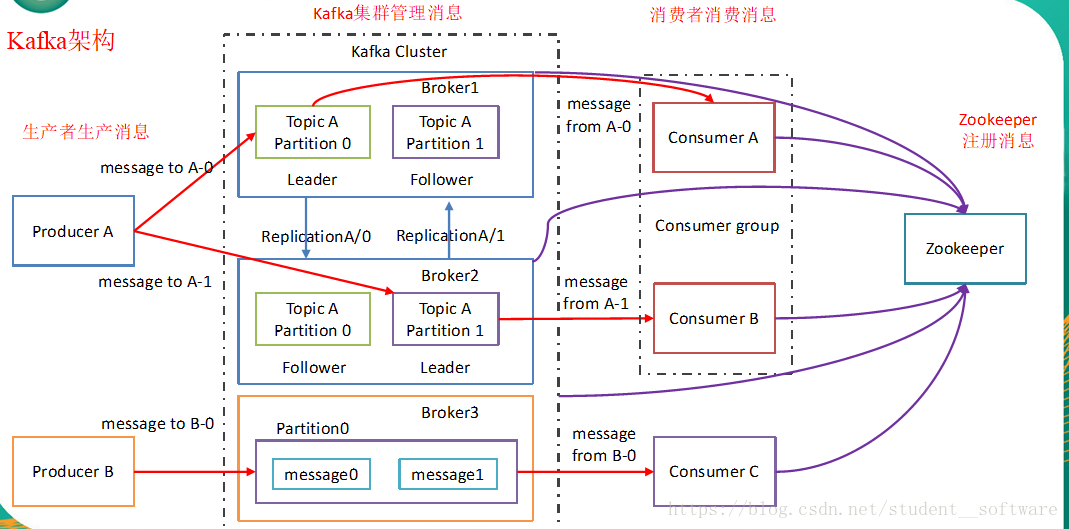
kafka如何做到高可用的?¶
从topic的Partition的副本来看:
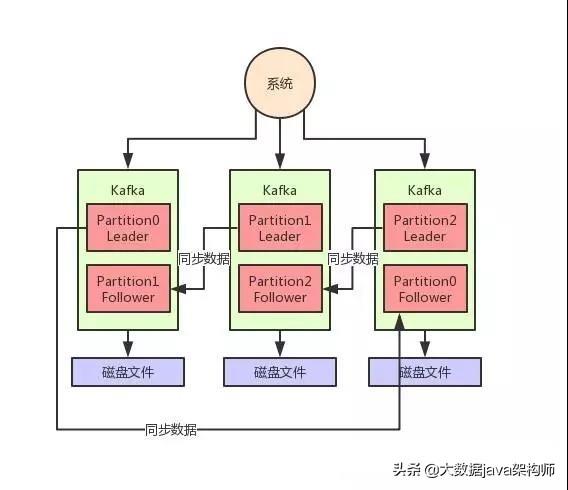
上图中只有一个Topic,它有3个Partition。
Kafka 为什么不支持读写分离?¶
自 Kafka 2.4 之后,Kafka 提供了有限度的读写分离,也就是说,Follower 副本能够对外提供读服务。
- 业务场景不适用。读写分离适用于那种读负载很大,而写操作相对不频繁的场景,可 Kafka 不属于这样的场景。
- 同步机制。Kafka 采用 PULL 方式实现 Follower 的同步,因此Follower 与 Leader 存 在不一致性窗口。如果允许读 Follower 副本,就势必要处理消息滞后(Lagging)的问题。
如何解决kafka消息重复消费问题?¶
将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。这个解决办法适合其他消息系统。
Kafka消息是采用Pull模式,还是Push模式?¶
kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送(push)到broker,consumer从broker拉取(pull)消息。同redis的bpop命令类似,Kafka有个参数可以让consumer阻塞知道新消息到达,可以防止consumer不断在循环中轮询。
kafka中如何防止消息丢失?¶
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
-
0
表示producer不等待来自broker同步完成的确认继续发送下一条消息;
-
1
表示producer在leader已成功收到的数据并得到确认后发送下一条message,默认状态
-
-1
表示producer在header,follower副本确认接收到数据后才算一次发送完成;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
可见在同步模式下,ack=-1时候,可以防止消息丢失。但这牺牲了吞吐量。
kafka中的 zookeeper 起到什么作用,可以不用zookeeper吗?¶
早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
kafka 为什么那么快?¶
-
Page cache技术
Kafka每次接收到数据都会往磁盘上去写。但并不是直接写入磁盘的,而是写入OS cache上面,然后在写到磁盘
-
顺序读写磁盘
磁盘读写时候,是顺序读写的。此时数据在磁盘上存取代价为O(1)。
-
零拷贝技术
Customer从broker读取数据,采用零拷贝技术。将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
传统的数据发送需要发送4次上下文切换,采用sendfile系统调用之后,数据直接在内核态交换,系统上下文切换减少为2次。
Kafka中是怎么体现消息顺序性的?¶
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1。
kafka如何实现延迟队列?¶
kafka基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。
kafka中consumer group 是什么概念?¶
consumer group是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
Kafka 中位移(offset)的作用?¶
在 Kafka 中,每个 主题分区下的每条消息都被赋予了一个唯一的 ID 数值,用于标识它在分区中的位置。这个 ID 数值,就被称为位移,或者叫偏移量。一旦消息被写入到分区日志,它的位移值将不能 被修改。
阐述下Kafka 中的领导者副本(Leader Replica)和追随者副本 (Follower Replica)的区别?¶
Kafka 副本当前分为领导者副本和追随者副本。只有 Leader 副本才能 对外提供读写服务,响应 Clients 端的请求。Follower 副本只是采用拉(PULL)的方 式,被动地同步 Leader 副本中的数据,并且在 Leader 副本所在的 Broker 宕机后,随时准备应聘 Leader 副本。
自 Kafka 2.4 版本开始,社区通过引入新的 Broker 端参数,允许 Follower 副本有限度地提供读服务。
消息传递语义是什么概念?¶
message delivery semantic 也就是消息传递语义。通用的概念,也就是消息传递过程中消息传递的保证性。分为三种:
-
最多一次(at most once)
消息可能丢失也可能被处理,但最多只会被处理一次。可能丢失,不会重复。
只管发送,不管对方收没收到。
-
至少一次(at least once)
消息不会丢失,但可能被处理多次。可能重复 不会丢失。
发送之后,会等待对方确认之后才会停止发送。
-
精确传递一次(exactly once)
消息被处理且只会被处理一次。不丢失,不重复,就一次。
介绍一下beanstalk?¶
beanstalk是轻量级的,易使用的,C语言实现的消息队列中间件。支持特性有:
-
延迟(delay)
延迟意味着可以定义任务什么时间才开始被消费
-
优先级(priority)
优先级就意味 支持任务插队(数字越小,优先级越高,0的优先级最高)
-
持久化(persistent data)
Beanstalkd 支持定时将文件刷到日志文件里,即使beanstalkd宕机,重启之后仍然可以找回文件
-
任务超时重发(time-to-run)
消费者必须在指定的时间内处理完这个任务,否则就认为消费者处理失败,任务会被重新放到队列,等待消费
Beanstalk由四部分构成:
-
管道(tube)
相当于kafka的Topic概念,是消息的归类。
-
任务(job)
相当于kafka中的消息
-
producer
job的生产者,通过put命令来将一个job放到一个tube中
-
consumer
job的消费者,通过reserve、release、bury、delete命令来获取job或改变job的状态
任务从进入管道到离开管道一共有5个状态(ready,delayed,reserved,buried,delete):
-
生产者将任务放到管道中,任务的状态可以是ready(表示任务已经准备好,随时可以被消费者读取),也可以是delayed(任务在被生产者放入管道时,设置了延迟,比如设置了5s延迟,意味着5s之后,这个任务才会变成ready状态,才可以被消费者读取)
-
消费者消费任务(消费者将处于ready状态的任务读出来后,被读取处理的任务状态变为reserved),可以设置reserved的时间,若在这段时间没有处理完成,那么任务会重新放回消息队列中,再次被别人消费
-
消费者处理完任务后,任务的状态可能是delete(删除,处理成功),可能是buried(预留,意味着先把任务放一边,等待条件成熟还要用),可能是ready,也可能是delayed,需要根据具体业务场景自己进行判断定义